Shared Visual Representations in Human and Machine Intelligence (SVRHM)
2020 NeurIPS Workshop | Dec. 12, 2020 | Virtual | Workshop Website
The goal of the Shared Visual Representations in Human and Machine Intelligence (SVRHM) workshop is to disseminate relevant, parallel findings in the fields of computational neuroscience, psychology, and cognitive science that may inform modern machine learning methods.
In the past few years, machine learning methods—especially deep neural networks—have widely permeated the vision science, cognitive science, and neuroscience communities. As a result, scientific modeling in these fields has greatly benefited, producing a swath of potentially critical new insights into human learning and intelligence, which remains the gold standard for many tasks. However, the machine learning community has been largely unaware of these cross-disciplinary insights and analytical tools, which may help to solve many of the current problems that ML theorists and engineers face today (e.g., adversarial attacks, compression, continual learning, and self-supervised learning).
Thus we propose to invite leading cognitive scientists with strong computational backgrounds to disseminate their findings to the machine learning community with the hope of closing the loop by nourishing new ideas and creating cross-disciplinary collaborations.
- Opening Remarks
- Martin Hebart (Max Planck Institute for Human Cognitive and Brain Sciences) | "THINGS: A large-scale global initiative to study the cognitive, computational, and neural mechanisms of object recognition in biological and artificial intelligence"
- David Mayo (Massachusetts Institute of Technology) | "Characterizing models of visual intelligence"
- Tim Kietzmann (Donders Institute for Brain, Cognition and Behaviour) | "It's about time. Modelling human visual inference with deep recurrent neural networks."
- S.P. Arun (Indian Institute of Science) | "Do deep networks see the way we do? Qualitative and quantitative differences"
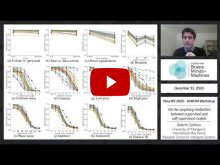
- Robert Geirhos (University of Tübingen & International Max Planck Research School for Intelligent Systems) | "On the surprising similarities between supervised and self-supervised models" | [Invited Oral from Submitted Papers]
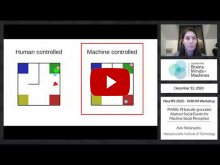
- Aviv Netanyahu (Massachusetts Institute of Technology) | "PHASE: PHysically-grounded Abstract Social Events for Machine Social Perception" | [Invited Oral from Submitted Papers]
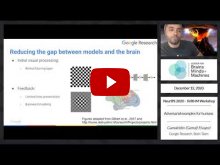
- Grace Lindsay (University College London) | "Modeling the influence of feedback in the visual system"
- Leyla Isik (Johns Hopkins University) | “Social visual representations in humans and machines”
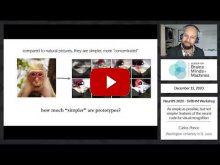
- Carlos Ponce (Washington University in St. Louis) | "As simple as possible, but not simpler: features of the neural code for visual recognition"
- Aude Oliva: (Massachusetts Institute of Technology) | "Resolving Human Brain Responses in Space and Time"
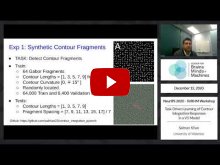
- Salman Khan (University of Waterloo) | "Task-Driven Learning of Contour Integration Responses in a V1 Model" | [Invited Oral from Submitted Papers]
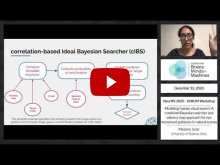
- Melanie Sclar (University of Buenos Aires) | "Modeling human visual search: A combined Bayesian searcher and saliency map approach for eye movement guidance in natural scenes" | [Invited Oral from Submitted Papers]
- Bria Long (Stanford University) | "Parallel developmental changes in children's drawing and recognition of visual concepts."
- Gamaleldin Elsayed (Google Brain) | "Adversarial examples for humans"
- Miguel Eckstein (University of California, Santa Barbara) | "Visual Search: Differences between your Brain and Deep Neural Networks"
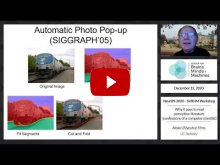
- Alyosha Efros (University of California, Berkeley) | "Why it pays to study Psychology: Lessons from Computer Vision"
- Concluding Remarks, Diversity in AI Best Paper Award (NVIDIA Titan RTX) Ceremony and Oculus Quest Award for Breakthrough in Biologically inspired Generative Models.