CVPR 2015 Language and Vision Workshop
 Thursday, 11 June 2015 - Boston, Massachusetts
Thursday, 11 June 2015 - Boston, Massachusetts
This workshop was co-organized by CBMM, Istituto Italiano di Tecnologia (IIT), MIT, Stanford University, UCLA, and the University of Surrey.
Event website: languageandvision.com
Speakers
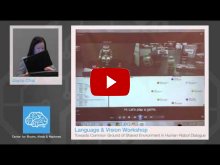
- Joyce Chai, Michigan State University - "Towards Common Ground of Shared Environment in Human-Robot Dialogue"
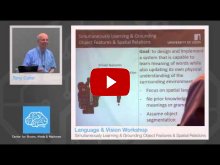
- Tony Cohn, University of Leeds - "Simultaneously Learning and Grounding Object Features and Spatial Relations"
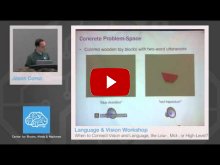
- Jason J. Corso, University of Michigan - "When to Connect Vision and Language, the Low-, Mid- or High-Level?"
- Kristen Grauman, University of Texas at Austin - "Learning the Right Thing with Visual Attributes"
- Andrej Karpathi, Fei Fei Li, Stanford - "Automated Image Captioning with ConvNets and Recurrent Nets"
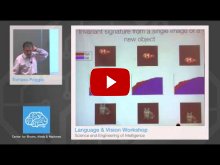
- Tomaso Poggio, MIT - "Science and Engineering of Intelligence"
- Jeffrey Mark Siskind, Purdue University - "Computers and Vision and Language"
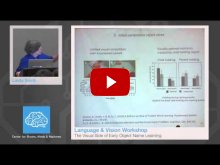
- Linda Smith, Indiana University, Bloomington - "The Visual Side of Early Object Name Learning"
- Stefanie Tellex, Brown University - "Human-Robot Collaboration"
- Patrick Winston, MIT - "The Vision Story"
- Song-Chun Zhu, UCLA - "Restricted Turing Test for Scene and Event Understanding
Call
The interaction between language and vision, despite seeing traction as of late, is still largely unexplored. This is a particularly relevant topic to the vision community because humans routinely perform tasks which involve both modalities. We do so largely without even noticing. Every time you ask for an object, ask someone to imagine a scene, or describe what you're seeing, you're performing a task which bridges a linguistic and a visual representation. The importance of vision-language interaction can also be seen by the numerous approaches that often cross domains, such as the popularity of image grammars. More concretely, we've recently seen a renewed interest in one-shot learning for object and event models. Humans go further than this using our linguistic abilities; we perform zero-shot learning without seeing a single example. You can recognize a picture of a zebra after hearing the description "horse-like animal with black and white stripes" without ever having seen one.
Furthermore, integrating language with vision brings with it the possibility of expanding the horizons and tasks of the vision community. We have seen significant growth in image and video-to-text tasks but many other potential applications of such integration – answering questions, dialog systems, and grounded language acquisition – remain unexplored. Going beyond such novel tasks, language can make a deeper contribution to vision: it provides a prism through which to understand the world. A major difference between human and machine vision is that humans form a coherent and global understanding of a scene. This process is facilitated by our ability to affect our perception with high-level knowledge which provides resilience in the face of errors from low-level perception. It also provides a framework through which one can learn about the world: language can be used to describe many phenomena succinctly thereby helping filter out irrelevant details.
Topics covered:
- language as a mechanism to structure and reason about visual perception,
- language as a learning bias to aid vision in both machines and humans,
- novel tasks which combine language and vision,
- dialog as means of sharing knowledge about visual perception,
- stories as means of abstraction,
- transfer learning across language and vision,
- understanding the relationship between language and vision in humans,
- reasoning visually about language problems, and
- joint video and language parsing.
The workshop also included a challenge related to the 4th edition of the Scalable Concept Image Annotation Challenge one of the tasks of ImageCLEF. The Scalable Concept Image Annotation task aims to develop techniques to allow computers to reliably describe images, localize the different concepts depicted in the images and generate a description of the scene. The task directly related to this workshop is Generation of Textual Descriptions of Images.
Contributions to the Generation of Textual Descriptions challenge were also showcased at the poster session, and a summary of the results were be presented at the workshop.
Organizers
Andrei Barbu, Postdoctoral Associate, MIT
Georgios Evangelopoulos, Postdoctoral Fellow, Istituto Italiano di Tecnologia and MIT
Daniel Harari, Postdoctoral Associate, MIT
Krystian Mikolajczyk, Reader in Robot Vision, University of Surrey
Siddharth Narayanaswamy, Postdoctoral Scholar, Stanford University
Caiming Xiong, Postdoctoral Associate, UCLA
Yibiao Zhao, PhD student, UCLA