Our goal in the Center has been to create a new field by bringing together computer scientists, cognitive scientists and neuroscientists to work in close collaboration. The new field—the Science and Engineering of Intelligence—is dedicated to developing a curiosity driven, computational understanding of human intelligence and to establishing an engineering practice based on that understanding.
In the first five years of CBMM, our five thrusts addressed the questions of (1) how human intelligence develops during childhood, (2) how it is grounded in computation, (3) how these computations are implemented in neural systems, (4) how social interaction amplifies the power of these computations, and (5) which mathematical theories can capture the key motifs of intelligence. For the next five years, our new proposal, which was approved for funding by NSF, focused on understanding and replicating visual intelligence, which is one of the moonshot projects that we have formulated for future research, and which we describe below.
After more than four years of joint research on broad themes, CBMM has developed an interdisciplinary language and approach strongly shared among the PIs. We are now focusing our team on a new single Center Project consisting of a set of interconnected modules. The modules reflect a hypothetical computational architecture of the visual system. We conjecture that the main goal of intelligent vision is a rich representation of the environment around an observer, corresponding to the conscious illusion of perceiving the constant, whole world around us. We call this a “3 ½ D sketch,” in reference to the “2 ½ D sketch” that David Marr (“Vision,” 2010 edition) famously used to describe the way that the 2D images available to our retinae are somehow combined to form an internal 3D model of the visual world. We extend the metaphor to “3 ½ D” because visual perception contains much more information than 3D geometry, as we will describe later. Our working hypothesis is that such a representation of the environment is rich enough to allow us to act on the world around us and to react to events that take place in it. Such a representation enables and reflects computations that detect objects and other people and their interactions, interpret distances, relative order and movement, allows navigation, grasping, and abstract scene understanding, not to mention long-term planning and reasoning.
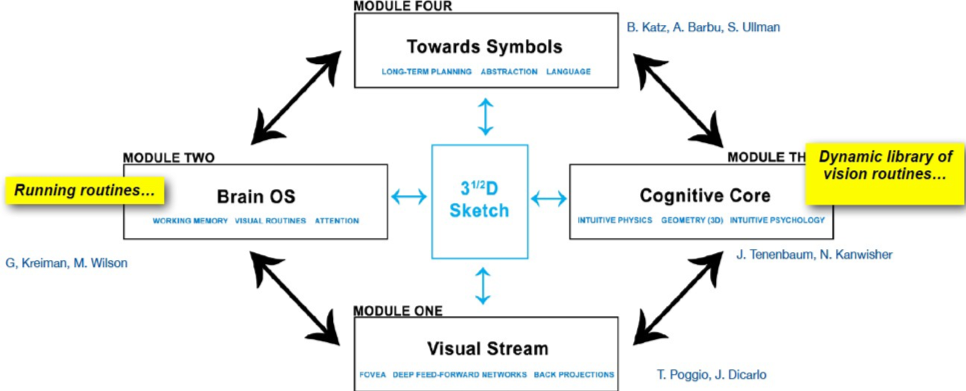
At the computational level we regard the system corresponding to perceptual intelligence as consisting of the four main, interacting modules shown in Figure 1. The figure presents in a simplified manner our working hypothesis, including the main computational modules. The visual stream of perceptual information starts in V1 with the equivalent of approximately 5 image-like arrays — with 30 by 30 elements covering the central 5 degrees, roughly corresponding to the fovea. These arrays represent image information over domains of increasing diameter and decreasing resolution, from 0.5 degree diameter at the highest resolution, which we may call the foveola, to 5 degrees at the lowest. They are all centered at the focus of gaze. This visual information, processed through visual areas up to IT, is compressed in a number of channels comprising a sort of visual dictionary (Mairal et al., 2008) with different degrees of selectivity and invariance. The 3 ½ D sketch covers the environment around us and is created by gluing together the images patches contributed by each saccade. It is created and maintained by eye movements. It is the blackboard read and written by the computational equivalent of an Operating System (OS), which relies on task-dependent routines that incorporate expertise in qualitative geometry, physics, and psychology. The OS and its routines lead to visual based decisions and actions but that we do not plan to study the associated motor control systems in this proposal. For various points of view on perceptual intelligence see (Anderson, 1983; Mumford, 1992; Ullman, 1996; Ahissar and Hochstein, 2004; Elman, 2005).