September 3rd - 5th, 2015 | McGovern Institute for Brain Research, MIT

The Center for Brains Minds and Machines (CBMM) is organizing a workshop on "Understanding Face Recognition: neuroscience, psychophysics and computation" from 3:30pm on September 3rd to 1pm on September 5th, 2015, at MIT in Cambridge. Attendance to workshop is by invitation only.
At the workshop we plan to present the first of the Turing++ Questions , see the CBMM Turing++ Questions. The focus of the workshop will be on face recognition -- the answer to the question: who is there? Because our aim is to understand the brain and to replicate human intelligence, we will present computational models of face recognition in the primate brain and evaluate them in terms of human behavior and primate physiology, including fMRI, MEG and single units recordings. The discussion at the workshop will bring together experts in artificial intelligence, neuroscience, and behavioral sciences. We hope you will be able to participate and contribute to the talks and the discussion.
Review of the CBMM workshop on the Turing++ Question: ‘who is there?
From 3rd to the 5th of September 2015, the Center for Brains Minds and Machines hosted a workshop to addressed the first Turing++ Question: ‘who is there?’. The workshop invited experts from the fields of computer vision, cognitive science and neuroscience to engage in a discussion about what are the neural algorithms and the underlying neural circuits that support the ability of humans and other primates to recognize faces. Participants included: Takeo Kanade, Isabelle Bulthoff, Robert Desimone, Nancy Kanwisher, Anil Jain, Gabriel Kreiman, Thomas Vetter, Winrich Freiwald, Lior Wolf, Cheston Tan, Qianli Liao, Ilker Yildirim, Alice O’Toole, Pawan Sinha, Jim DiCarlo, Arash Afraz, Ken Nakayama, Matt Peterson, and Elias Issa, along with the co-organizers Tomaso Poggio and Ethan Meyers.
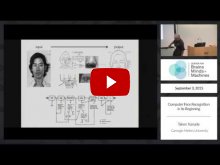
The workshop started on the afternoon of September 3rd with a session on the historical developments in these different fields. Takeo Kanade gave the first talk in which he spoke about the early development of computer vision systems in the 1960’s and 1970’s when computational constraints were a major bottleneck. Despite the limited ability of these early systems, there were many take way messages that still hold today including the fact that many models that are currently used are a continuation of the ideas from these early systems, and that technology advancement (i.e., faster computing power) might be one keys to creating better systems. The second talk was given by Isabelle Bulthoff in which she spoke about the development of psychophysics of face processing which research started taking off in the 1970’s. Despite many significant advances in the field, many of the central questions that were focused on during this period still have not been solved today. The third talk was given by Robert Desimone in which spoke about some of the first electrophysiology work in macaque monkeys that occurred in the early 1980’s. During that time it was thought that information was coded in highly distributed manner and so the initial reports that single neurons could be highly selective for only faces was initially met with skepticism; however with the ability to record repeatedly from the same animal, and the rise of computational data analyses, most researchers in the field become convinced of the findings. The fourth talk was given by Nancy Kanwisher in which she spoke about the first neuroimaging studies of faces in the early 1990’s and how using region of interest analyses avoided many of the statistical issues that confronted researchers who were faced with thousands of individual recordings from the new PET and fMRI recordings technologies. Finally, Anil Jain closed the session by talking about the current developments in the face identification in computer vision and how the field has been making increasing progress through the years.
The second session was held in the morning of September 4th and was the first session to focus on current research topics in face processing. The session started with a talk by Thomas Vetter who discussed his work on 3D face animation, and also whether 3D information was needed for face identification or only for computer graphics. This talk was followed by a talk by Winrich Freiwald who spoke about his work identifying facial features that neurons in different macaque face patches responded to. Many interesting findings were highlighted including the fact that all neurons in particular face patches seemed to increase their firing rates to larger iris sizes, while for other facial features, neurons responded to the extremes of facial features in either direction (e.g., some neurons responded maximally to very wide faces while other responded to very narrow faces). The third talk in the session was given by Lior Wolf who spoke about scaling machine learning methods to very large face data sets, which can dramatically increase the performance of these methods. The fourth talk was given by Cheston Tan who spoke about how faces are processed holistically, and how a computational system, based on the HMAX model, could account for this effect if one were to template with very large receptive fields. This session then concluded with a panel discussion led by Josh Tenenbaum and Amnon Shashua that discussed connections between the different talks, particularly with regard to whether 3D information was needed for face identification.
The third session of the workshop was held on the afternoon of the 4th and focused on two prosed computational models of face processing. The first model was presented by Qianli Liao and was based on a modified version of the HMAX model. This model was very compelling because not only was it biologically plausible, but also because it could achieve a high level of face identification accuracy on the Labeled Faces in the Wild data set without having to first align facial features in the images. The second model was presented by Ilker Yildirim and was based on a 3D analysis-by-synthesis approach where a convolutional neural network was used to efficiently fit the parameters of the 3D model. The advantage of this model was that it could perform well on unusual views of a face (e.g., the back of the head), although questions remain about whether this type of 3D model is biologically plausible.
The fourth session was also held on the afternoon of the 4th and focused on how to evaluate whether computational models were accurately capturing how neural systems are working. The first talk in this session was giving by Alice O’Toole and focused on a comparison of human and computer vision systems. The talk discussed how computer vision systems are currently better than humans on recognizing unfamiliar faces, however humans are better on recognizing familiar faces and using other body motion cues to identify individuals. The second talk in the session was given by Pawan Sinha, and focused on some strengths of the humans visual system to recognize faces under highly degraded conditions (such as very low resolution images) that currently far exceed the ability of computer vision systems. The final talk of the session was given by Jim DiCarlo in which he spoke about the relationship between face processing compared to the processing of non-face objects in neural systems. The session concluded with another panel discussion that focused on what data would be useful for constraining models and for moving the field forward.
The final session of the workshop was held on the morning of the 5th, and was the second session to focus on current research topics in face processing. The first talk was given by Arash Afraz who spoke about his work using muscimol and optogenetics to silence cells in face patches. The results of his study showed that if only a subset of cells was silenced, the behavioral effects were rather small, however when wider deactivation was used, dramatic behavioral effects could be induced. The second talk was given by Ken Nakayama in which he talked about how online experiments could be very effective to estimate a range of human recognition abilities (from prosopagnosics to super recognizers). The third talk in the session was given by Matt Peterson who spoke about using eye-tracking to understand face processing. His results showed that people are fixate very consistently on specific regions of the face, and that different people fixate on different regions (e.g., some people fixate on the region between the eyes while others fixate closer to the mouth). The least talk was given by Elias Issa who discussed how neurons in the face patches respond to images of inverted faces. The results showed that neural responses to inverted faces were delayed and often larger than the responses to upright faces, and a model was proposed in which error signals are propagated between different face patch regions. This session ended with a panel discussion led by Gabriel Kreiman which consisted of a brainstorming sessions about what resources and knowledge would be useful for advancing our understanding of face identification. It was proposed that a website that would allow researchers to compare neural data, behavioral results and computational models would be very useful for moving the field forward. Based on this discussion, the CBMM is currently building such a system which should be available to researchers by the middle of 2016. Overall the workshop was incredibly valuable for sharing knowledge about how different disciplines study face processing, highlighting what are the key challenges for developing a computational understanding of the neural algorithms that underlie face identification, and for generating ideas about what would be the next best steps to pursue to make progress.
A few selected abstracts from the workshop are below:
Lior Wolf : Web-Scale Training for Face Identification
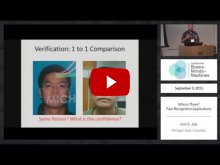
Scaling machine learning methods to very large datasets has attracted considerable attention in recent years, thanks to easy access to ubiquitous sensing and data from the web. We study face recognition and show that three distinct properties have surprising effects on the transferability of deep convolutional networks (CNN): (1) The bottleneck of the network serves as an important transfer learning regularizer, and (2) in contrast to the common wisdom, performance saturation may exist in CNN's (as the number of training samples grows); we propose a solution for alleviating this by replacing the naive random subsampling of the training set with a bootstrapping process. Moreover, (3) we find a link between the representation norm and the ability to discriminate in a target domain, which sheds lights on how such networks represent faces. Based on these discoveries, we are able to improve face recognition accuracy on the widely used LFW benchmark, both in the verification (1:1) and identification (1:N) protocols, and directly compare, for the first time, with the state of the art Commercially-Off-The-Shelf system and show a sizable leap in performance.
Winrich Freiwald: On the Functional Organization of Neural Face-Processing Systems
Research into the neural mechanisms of face recognition has uncovered a wide range of empirical facts about biological face processing systems from single neurons to areas and behavior. In my presentation, I will give an overview over the different empirical results, primarily obtained in macaque monkeys and humans, on the functional organization of face-processing systems and their embedding into the primate brain. I will highlight principles of this functional organization and how they may impact neural information processing. I will discuss putative links to the psychophysics of human face recognition and lacks in our current knowledge, and point out potential links to theory.
Alice O’Toole: Comparing face (and person) recognition by humans and computers
Over the past decade, face recognition algorithms have shown impressive gains in performance, operating under increasingly unconstrained imaging conditions. It is now commonplace to benchmark the performance of automatic face recognition algorithms against humans. I will present a short history of human-machine comparisons, which began in conjunction with U.S. Government-sponsored competitions for computer-based face recognition systems. I will extend this topic to discuss the literature of the past few years in which human-benchmarking is undertaken using Mechanical Turk workers. I will discuss methodological issues that bear on interpreting and comparing these benchmarks. Overall, I will argue that human-machine comparisons have provided insight into the strengths and weaknesses of both humans and machines. I will conclude that human expertise for “face recognition” is better described and understood in the context of the whole person in motion—where the body and gait provide valuable identity information that supplements the face in poor viewing conditions.
Thomas Vetter: Probabilistic Morphable Models
The analysis of face images has many aspects reaching from face identification to social judgement or to medical questions. In our research we aim on a single unifying approach for these tasks. The core of our approach is an analysis by synthesis loop using a 3D morphable face model. In this talk I will extend our earlier morphable models formalism with the concept of gaussian processes. Second, I present a Data Driven Markov Cain Monte Carlo scheme for a fitting of morphable models to images able to integrate unreliable bottom-up cues. Based on various face image analysis tasks I will demonstrate the advantage of generative models and discuss also current limitations of our model and approach.
Pawan Sinha: Face Recognition by Humans: Proficiencies and Peculiarities
In order for a machine to mimic human face recognition performance, and possibly serve as a model of the underlying biological processes, it needs to capture the latter's strengths as well as frailties, and also respond to input transformations in a manner akin to a human. I shall review findings from human studies that may serve as a partial desiderata for artificial vision systems.
Ken Nakayama : Face recognition from an individual differences perspective
We have a new opportunity thanks to the capacities of the internet to do behavioral and possibly genomic research. Our platform, TestMyBrain.org, has recruited over 1.3 million participants, who have volunteered their brains in a citizen science enterprise. This enables us to ask a number of questions which have been difficult if not impossible to address with previous methods. This includes aspects of modularity (specialization), inheritance, environment, and robustness.
Isabelle Bülthoff: History of face identification
While face appearance has attracted attention since the antiquity, scientific investigation of face identification has developed much later. This talk will give a very short overview of some of the main aspects of human face identification: e.g. differences between familiar and unfamiliar faces, holistic processing and investigating face identification in a more natural context.
Cheston Tan: Towards a Turing++ understanding of holistic face processing
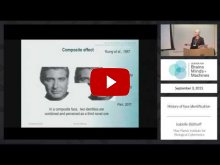
Abstract: Faces are a class of visual stimuli with unique significance, for a variety of reasons. One way in which faces are special is that they have been empirically found to be processed holistically, based on a number of well-known behavioral effects. However, not much is known about the computational and neural mechanisms – and the connections between behavior, computation and neurobiology – underlying such holistic face processing. In this computational modeling work, we show that a single factor – neural tuning size – is able to account for three “gold standard” behavioral phenomena that are characteristic of face processing, namely the Composite Face Effect (CFE), Face Inversion Effect (FIE) and Whole-Part Effect (WPE). In other words, our computational proof-of-principle proposes specific neural tuning properties that result in holistic face processing. Overall, for the holistic aspects of face processing, we may have one possible path towards a Turing++ understanding.
Elias Issa: Neural dynamics in the primate ventral visual cortex during face processing
Object recognition is thought to result from feedforward processing in a series of hierarchically arranged stages in the primate ventral visual stream. Here, we focussed on face processing in an intermediate stage of the hierarchy, posterior inferior temporal cortex (IT). In posterior IT, we observed late-phase neural dynamics beyond those present in the feedforward response. This temporal evolution of neural responses was incompatible with signal propagation in a pure feedforward model or extensions implementing adaptation, lateral inhibition, or normalization. Instead, we found that the dynamical signatures of IT neurons encoded error signals. This interpretation of neural activity as error coding accounted for a number of seemingly disparate neural phenomena observed in previous experiments and shed light on how a cortical area recurrently combines both bottom-up and top-down information.
Ilker Yildirim: Efficient analysis-by-synthesis in primate face processing
A glance at an object is often sufficient to recognize it and recover fine details of its shape and appearance, even under highly variable viewpoint and lighting conditions. How can vision be so rich, but at the same time fast? The analysis-by-synthesis approach to vision offers an account of the richness of our percepts, but it is typically considered too slow to explain perception in the brain. In this talk, I will propose a version of analysis-by-synthesis in the spirit of the Helmholtz machine (Dayan, et al., 1995) that can be implemented efficiently, by combining a generative model based on a realistic 3D computer graphics engine with a recognition model based on a deep convolutional network. The recognition model initializes inference in the generative model, which is then refined by brief runs of MCMC. We evaluate our approach in the domain of face recognition: it can reconstruct the approximate shape and texture of a novel face from a single view, at a level indistinguishable to humans; it accounts for human behavior in "hard" recognition tasks; and it matches neural responses in a network of face-selective brain areas.