| Title | Complexity Control by Gradient Descent in Deep Networks |
| Publication Type | Journal Article |
| Year of Publication | 2020 |
| Authors | Poggio, T, Liao, Q, Banburski, A |
| Journal | Nature Communications |
| Volume | 11 |
| Date Published | 02/2020 |
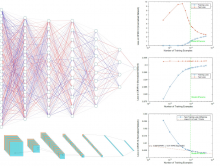
| Abstract | Overparametrized deep network predict well despite the lack of an explicit complexity control during training such as an explicit regularization term. For exponential-type loss functions, we solve this puzzle by showing an effective regularization effect of gradient descent in terms of the normalized weights that are relevant for classification. |
| URL | https://www.nature.com/articles/s41467-020-14663-9 |
| DOI | 10.1038/s41467-020-14663-9 |
Download:
 s41467-020-14663-9.pdf
s41467-020-14663-9.pdf
Associated Module:
CBMM Relationship:
- CBMM Funded
 Qianli Liao, Tomaso Poggio, and Andrzej Banburski stand with their equations. Image: Kris Brewer")